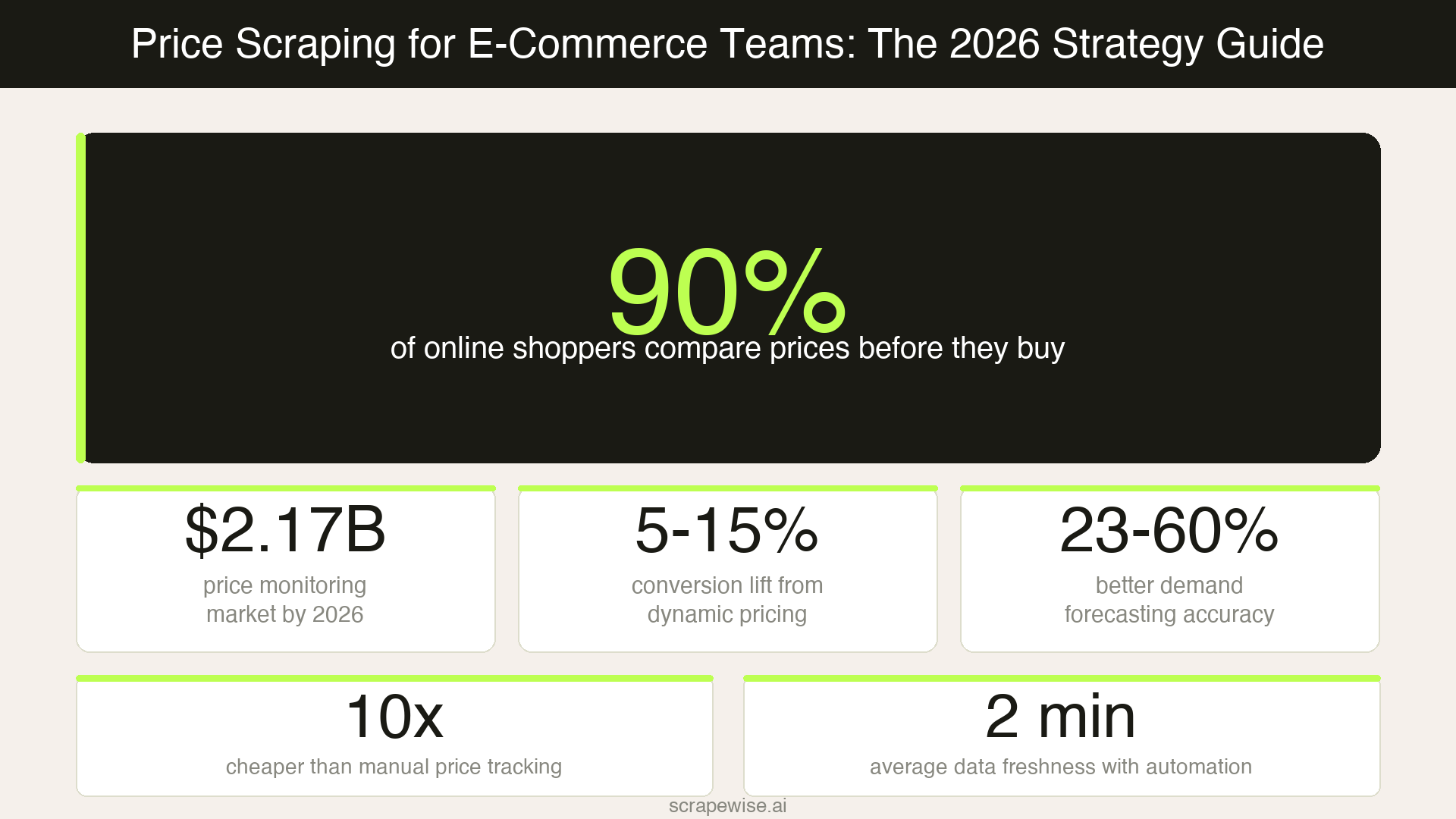
Nine out of ten online shoppers compare prices before they buy. That single fact explains why price scraping has moved from a developer experiment to a frontline business tool for e-commerce teams. If you don't know what your competitors are charging right now, you're pricing in the dark — and leaving revenue on the table.
The numbers back this up. According to Market.us, the global web scraping market reached $754 million in 2024 and is projected to hit $2.87 billion by 2034, with price and competitive intelligence extraction growing fastest at 19.8% CAGR. 81% of US retailers now use automated price scraping for dynamic repricing — up from just 34% in 2020. Meanwhile, Amazon alone changes prices 2.5 million times per day, making manual tracking physically impossible.
This guide is not a coding tutorial. It's a practical breakdown of what price scraping is, what data it gives you, and how to build it into your pricing workflow without touching a single line of code.
What Is Price Scraping?
Price scraping is the automated extraction of pricing data from competitor websites, marketplaces, and retail platforms. Instead of manually visiting sites and copying prices into a spreadsheet, a price scraper does it automatically — on a schedule, at scale, across hundreds or thousands of competitor SKUs.
The data collected typically includes:
- Current price (including sale, clearance, and bundled prices)
- Stock availability (in stock, out of stock, low inventory warnings)
- Promotional discounts and active coupon codes
- Shipping costs and delivery timeframes
- Historical price movements over days, weeks, or months
When this data flows into your pricing system or BI tool automatically, it replaces guesswork with evidence. You know — in near real time — when a competitor drops prices, runs a flash sale, or pulls a product from the market.
Why Price Scraping Matters in 2026
The price monitoring software market is projected to reach $2.17 billion in 2026. That growth reflects a shift in how e-commerce businesses compete. Retailers who invest in live competitor pricing data see measurable returns: companies using dynamic pricing report 5–15% increases in conversion rates, according to McKinsey's dynamic pricing research.
Organizations using real-time competitor pricing data also see demand forecasting accuracy improve by 23–60% — because when you understand competitor moves, you can anticipate demand shifts before they happen.
In European markets — where mid-size retailers compete directly with Amazon, Zalando, and regional category leaders — the margin for pricing errors is thin. A product priced 8% above the market average doesn't just lose a sale. It trains your visitors to look elsewhere, and it takes weeks to rebuild that trust.
Price scraping closes the information gap. It turns competitor pricing from a quarterly research exercise into a live operational feed.
What Price Scraping Unlocks for Your Team
Real-Time Competitor Price Monitoring
Manual price checks don't scale. Tracking 50 competitors across 5,000 SKUs — even with a dedicated analyst — means your pricing data is days out of date by the time it reaches the team.
Automated price monitoring means your team sees competitor price changes within hours. You can set alerts for specific thresholds — "notify me if any competitor drops below our price on this category" — build repricing rules, or use the live feed to make confident hold/adjust decisions.
This is especially valuable for promotional windows: Black Friday, seasonal sales, and mid-week flash events where a 12-hour lag in competitor intelligence means a missed window.
Product Catalog Intelligence
Price scraping isn't only about price. When you scrape a competitor's product page, you also collect product availability, variant selection, and assortment data. This feeds directly into category management: which products should you stock more of? Where are competitors selling out? What new SKUs are they adding?
E-commerce product data extraction at this level helps merchandising teams make stocking decisions with market evidence rather than gut instinct — particularly valuable for seasonal planning in Nordic and DACH markets where regional assortment differences are significant.
Dynamic Pricing and Repricing Automation
Static pricing is unsustainable in most categories. Flash sales, algorithmic repricing from marketplace competitors, and promotional cycles mean prices shift daily — sometimes hourly. Price scraping provides the input layer for dynamic pricing: live market data that your repricing tool or pricing team can act on immediately.
The teams getting the best results don't just react to competitor prices — they use scraped data to model price elasticity by category and build rules that hold margin while staying competitive. For a deeper look at how AI-driven pricing strategies are evolving, see our breakdown of the AI-native pricing revolution in retail.
MAP Monitoring and Reseller Compliance
If you sell through distributors or resellers, price scraping helps you verify whether your Minimum Advertised Price (MAP) policies are being respected across channels. Automated scraping across marketplace listings catches violators faster than any manual audit, protecting your margins and brand integrity before the damage compounds.
For a full treatment of this use case, see our guide to MAP monitoring and brand protection for e-commerce.
How Price Scraping Works — Without Any Code
The traditional mental model of price scraping involves Python scripts, proxy servers, and ongoing developer maintenance. That infrastructure is real — but for most e-commerce teams, it's a blocker, not a solution.
Modern no-code scraping platforms change this completely. You configure what you want to scrape (competitor URLs, specific data fields, update frequency), and the platform handles the technical layer: proxy rotation, JavaScript rendering, anti-bot bypass, scheduling, and structured data delivery.
With a platform like Scrapewise, the workflow looks like this:
- Add competitor URLs — product pages, category pages, or search results
- Map the fields — select the data you want: price, stock, title, variants
- Set a schedule — daily, hourly, or event-triggered
- Receive structured data — via API, CSV export, or direct BI integration
There's no code to maintain, no proxy infrastructure to manage, and no scraper that breaks when a competitor updates their site design. The platform handles that complexity. Your team just gets clean, structured data.
Price Scraping Challenges and How to Solve Them
Anti-Scraping Protections
Every major retailer and marketplace uses some form of bot detection — rate limiting, CAPTCHAs, IP blocking, or browser fingerprinting. A scraper that works today can fail tomorrow when a site updates its defenses.
The solution is managed infrastructure: platforms that rotate residential proxies, mimic human browsing behaviour, and self-heal when detection triggers. For a detailed look at how anti-bot technology works and how legitimate scrapers navigate it, see The Anti-Bot Arms Race.
Data Quality and Normalisation
Scraped price data is only useful if it's clean and consistent. Prices formatted as "€1.299,99" in Germany and "$1,299.99" in the US need to be normalised before they're comparable. Products need to be matched across competitors by EAN, GTIN, or title similarity.
Quality scraping platforms handle currency formatting, unit normalisation, and duplicate detection automatically. For how product matching works across scraped datasets — including AI-assisted matching for unstructured product titles — see our breakdown of product data matching in e-commerce.
JavaScript-Heavy Websites
Many modern retail sites load prices and inventory data dynamically via JavaScript — which means a basic HTML scraper won't see the actual price in the page source. The scraper needs to render the page as a browser would.
This is handled at the infrastructure level on modern platforms. For a technical overview of how JS-heavy e-commerce sites are scraped reliably, see how to scrape JavaScript-heavy e-commerce websites.
Legal Considerations
Price scraping of publicly available data is legal in most jurisdictions, including the EU and UK. You are collecting information that any human visitor can see — product names, prices, availability. Key requirements: don't bypass authentication, don't collect personal data, and respect robots.txt.
In 2026, some platforms updated their terms of service to restrict AI-driven agents that act on behalf of buyers. General price data collection for competitive intelligence remains well within legal boundaries — but a quick legal review for your specific use case and jurisdiction is always worthwhile.
Building a Price Scraping Workflow: Practical Steps
Step 1: Define your competitor set. Start with 10–20 domains and the SKUs that matter most — your top revenue categories, or the segments with the most price sensitivity. Don't try to scrape everything on day one.
Step 2: Decide on data freshness. Daily updates are sufficient for most retail categories. For fast-moving segments — consumer electronics, fast fashion, grocery — hourly scraping creates a real competitive advantage. Frequency affects cost, so match it to actual business need.
Step 3: Map your output. Where does the data need to land? A BI dashboard, a repricing tool, a shared spreadsheet, or an API your pricing system can poll? Define the output format before you configure the scraper — it shapes every other decision.
Step 4: Set up threshold alerts. The real power of live price data is acting on it fast. Configure alerts for price drops above a set percentage, stockouts at key competitors, or new SKUs appearing in competitor catalogs you don't stock.
Step 5: Review and iterate quarterly. Your competitor set changes. New marketplaces emerge. Promotional calendars shift. Revisit your scraping configuration every quarter and adjust targets as your competitive landscape evolves.
Price scraping is not a technical project — it's a business decision about how seriously you take your pricing strategy.
In 2026, the e-commerce teams winning on price aren't necessarily the ones with the lowest prices. They're the ones with the most current, most complete picture of what the market is doing. That picture starts with live competitor data, collected automatically, delivered cleanly, and acted on consistently.
If your team is still relying on weekly manual checks or static spreadsheets, you're already operating behind the market. The tools to close that gap work without a developer and start delivering value in the first week.
Paste a competitor URL — start tracking prices in 60 seconds
Any e-commerce site, any SKU count. Clean structured feeds on your schedule, no code required.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →