Product Data Extraction for E-commerce Teams
Eliminate manual data entry. Automate the collection of high-fidelity product details from any source to power your catalog enrichment, marketplace listings, and global syndication.
Eliminate manual data entry. Automate the collection of high-fidelity product details from any source to power your catalog enrichment, marketplace listings, and global syndication.
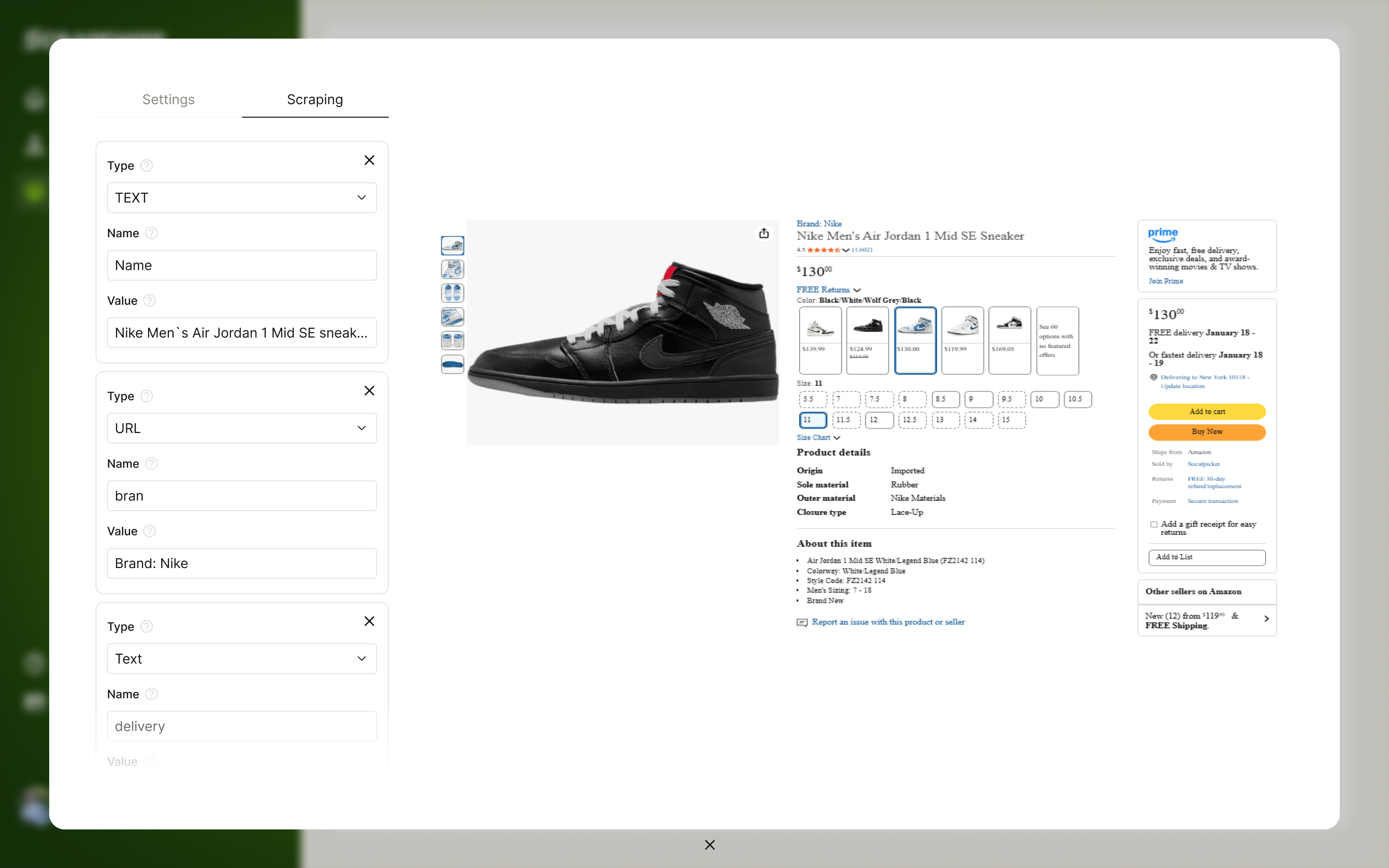
Every site layout change pulls your engineers off core work to fix broken scrapers and manage proxy rotations.
Your best talent wastes 80% of their day copy-pasting and reformatting raw HTML instead of driving business strategy.
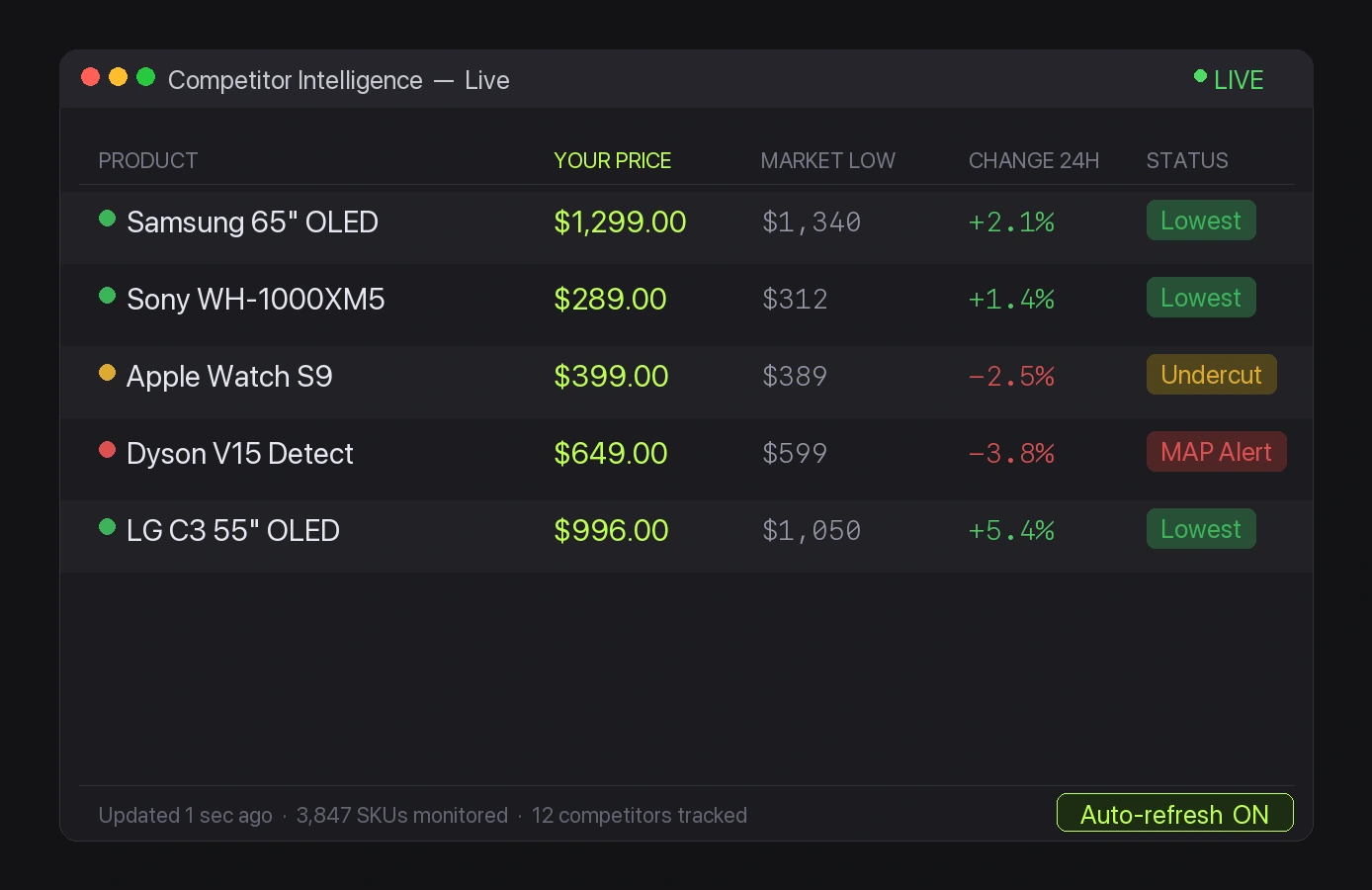
'Access Denied' blocks and inconsistent attributes create blind spots — decisions made on fragmented, unreliable data.
Dirty data breaks your PIM and ERP imports constantly, forcing reactive cleanup cycles that kill your speed-to-market.
A missed decimal at the source triggers wrong pricing, returns, and brand damage that takes weeks to trace and fix.
Of engineering time wasted on repetitive data extraction and script maintenance
Longer time-to-market when manually enriching product catalogs vs. automated extraction
Of catalog sync failures trace back to manual data entry and format inconsistencies
Automate the entire extraction-to-delivery pipeline. Replace thousands of hours of manual copy-pasting with scheduled, high-fidelity data syncs.
Onboard new supplier catalogs and enrich listings in hours, not weeks. Close the gap between market changes and your live site updates.
Eliminate the 'Accuracy Debt.' Automated normalization and validation ensure that every SKU, price, and attribute is 100% reliable before it hits your PIM.
Stop paying for maintenance debt. Most manual systems break within weeks. ScrapeWise uses resilient extraction technology that stays connected even when source sites change, saving you hundreds of engineering hours per year.
Scrape product titles, images, descriptions, pricing, specs, and more from supplier, retailer, or competitor websites.
Standardize formats, clean inconsistencies, and match duplicate entries to create clean product datasets.
Deliver product data via CSV or API into your PIM, ERP, CMS, or spreadsheet workflows — on your schedule.
ScrapeWise makes product data extraction effortless — helping your team save time, ensure consistency, and feed accurate content into every platform, from listings to back-end systems.
Everything you need to know about extracting and enriching product data with ScrapeWise.
Yes. ScrapeWise can extract titles, descriptions, pricing, availability, bullet points, specs, and media assets from product pages at scale.