Real estate data scraping has become the defining competitive edge in property investment. By the time a promising deal surfaces on Zillow or Rightmove, it has already been seen — and often reserved — by the teams running automated data pipelines. In 2026, the investors and PropTech teams winning deals are not necessarily the ones with more capital. They are the ones with better data, collected faster.
This guide covers exactly how real estate data scraping works, what data is worth extracting, and how to build a reliable pipeline — whether you're a PropTech platform processing millions of listings or an investment team tracking a specific market.
What Is Real Estate Data Scraping?
Real estate data scraping is the automated extraction of property information from public listing portals, MLS platforms, rental marketplaces, and real estate aggregators. Instead of manually browsing Zillow, Immobilienscout24, or Hemnet for hours, automated scrapers collect that data continuously — capturing price, location, square footage, listing date, condition, and dozens of other attributes — and deliver it in structured, queryable formats.
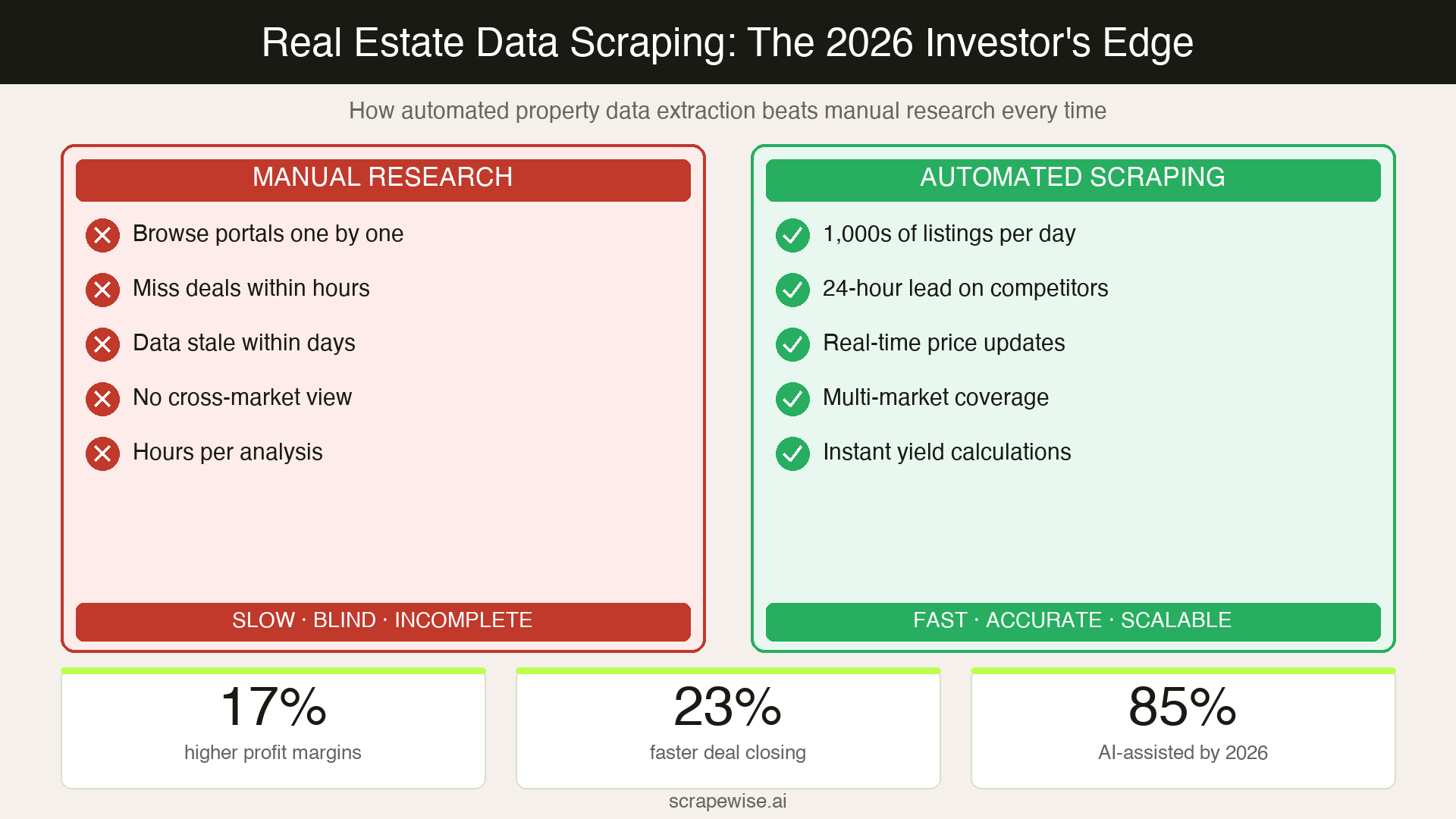
According to a Forrester Research survey, approximately 67% of real estate analytics companies now use web scraping as their primary method for building market intelligence. The Real Estate Technology Institute projects that by 2026, over 85% of real estate data collection will involve some form of AI-assisted extraction — a fundamental shift from the manual research workflows that still dominate smaller firms.
The data available from real estate portals is expansive. A single listing on a major platform typically contains 40–60 structured fields: list price, price per square metre, days on market, listing agent, property type, floor plan details, energy rating, nearby amenities, historical price changes, and estimated rental yield. At scale, that data becomes a real-time view of an entire market.
Why Real Estate Data Scraping Matters for Investors and PropTech Teams
The gap between firms with automated data pipelines and those without is widening fast. A recent Deloitte analysis found that real estate organisations with advanced data capabilities achieved 17% higher profit margins and 23% faster transaction completion than industry averages. That advantage compounds over time.
For investors, the use case is straightforward: find deals before the competition does. With 1.65 million homes listed for sale in the US as of January 2026 — and median prices at $423,261 — the market moves faster than manual research can track. Automated real estate data extraction allows analysts to screen thousands of listings per day, filter by specific investment criteria, and surface opportunities in minutes rather than weeks.
For PropTech teams, the stakes are different but the data dependency is the same. Platforms building automated valuation models (AVMs), rental yield calculators, neighborhood scoring systems, or acquisition pipelines all depend on continuous, accurate listing data. Without it, the product degrades — recommendations go stale, price estimates drift, and users stop trusting the platform.
The core use cases where real estate data scraping delivers direct value:
- Investment analysis: Screen properties against yield thresholds, price-per-sqm benchmarks, or days-on-market signals without manual filtering
- Market trend monitoring: Track inventory levels, median prices, and listing velocity across specific postcodes or neighbourhoods over time
- Rental yield calculation: Cross-reference for-sale data with rental listing data from the same catchment to calculate gross yield automatically
- Competitor intelligence: Monitor how rival agencies, developers, or platforms are pricing comparable stock and adjusting listings
- Automated valuation: Feed scraped comps data into valuation models as a continuous input rather than a quarterly refresh
What Data Can You Extract from Real Estate Sites?
Not all listing data is equally valuable. The fields worth prioritising depend on your use case, but a well-configured real estate scraper typically captures:
Pricing data:
- Listed price and price history (previous reductions, listing date)
- Price per square metre/foot by property type
- Estimated rental value (where listed)
- Auction reserve prices and results
Property attributes:
- Property type, bedrooms, bathrooms, floor area
- Energy Performance Certificate (EPC) rating — particularly relevant under EU and UK energy efficiency regulations
- Year built, condition, parking, outdoor space
- Floor level (for apartment blocks)
Market signals:
- Days on market
- Number of views or saves (where exposed by the platform)
- Listing agent and agency performance data
- Status changes (price reduction, sale agreed, withdrawn)
Location data:
- Precise GPS coordinates, postcode, neighbourhood designation
- Proximity to transport links, schools, amenities
- Flood risk zone, planning restrictions (from linked datasets)
For PropTech platforms building prediction models, the combination of listing attributes with market signal data — particularly days-on-market trends and price reduction frequency — is where the real value lies. According to Ahrefs' analysis of data-driven content strategies, original datasets built from automated extraction consistently outperform manually curated research in both accuracy and update frequency.
How Real Estate Data Scraping Works in 2026
Modern real estate portals are not designed to be scraped easily. Most major platforms — Zillow, Rightmove, Idealista, Immobilienscout24 — run heavily JavaScript-rendered frontends, deploy anti-bot protection from providers like Cloudflare and Akamai, and actively block datacenter IP addresses. A scraper built with standard libraries and a residential IP from 2021 will fail almost immediately against 2026-era defences.
Successful real estate data extraction at scale requires several layers working together:
1. JavaScript rendering: Property listing pages load data dynamically via React or Vue components. Scrapers need a full headless browser — or a platform that handles rendering — to access the content that actual users see.
2. Residential proxy rotation: Datacenter IPs are blocked on sight by major portals. Residential proxies that route requests through real ISP addresses are now the baseline requirement for reliable extraction. As covered in our guide to scraping JavaScript-heavy e-commerce websites, the same technical challenges that affect retail scraping apply directly to property portals.
3. Behavioural mimicry: Modern detection systems analyse mouse movement patterns, scroll velocity, request timing, and session length. Scrapers that navigate directly to data fields in milliseconds are flagged instantly. Human-like navigation patterns — with realistic dwell times and variable request cadences — are essential for sustained access.
4. Self-healing extraction logic: Real estate portals redesign pages frequently. A scraper targeting a CSS selector that breaks when Rightmove updates its listing template means hours of engineer time to diagnose and fix. Self-healing scraper infrastructure — which uses AI to understand page content semantically rather than targeting brittle selectors — keeps pipelines running through site changes without manual intervention.
5. Data normalisation: Listing data from different portals uses inconsistent formats. "3 bed semi-detached" on Rightmove needs to map to the same schema as "Reihenhaus, 3 Zimmer" on Immobilienscout24. A robust scraping pipeline includes a normalisation layer that standardises fields across sources so multi-market analysis is actually possible.
Platforms like ScrapeWise.ai handle these technical layers as managed infrastructure — delivering structured listing data as a continuous feed rather than requiring PropTech teams to build and maintain scraping systems themselves.
The European Real Estate Data Opportunity
European property markets present a specific and underserved opportunity for data-driven investors. Unlike the US — where Zillow and Redfin dominate with relatively centralised listing data — European listing data is fragmented across dozens of national platforms: Rightmove and Zoopla in the UK, SeLoger and Leboncoin in France, Immobilienscout24 and Immonet in Germany, Idealista in Spain, and local MLS equivalents in Nordic markets.
That fragmentation is an advantage for teams willing to aggregate across sources. An investment firm monitoring residential yields across Stockholm, Copenhagen, and Helsinki simultaneously — combining data from Hemnet, Boliga, and Etuovi — has a view that no single platform provides. That multi-market visibility is only possible through systematic data extraction.
European regulations add useful data points that US markets lack. EU Energy Performance Certificate (EPC) ratings, which are legally required on listings in most EU member states, provide a standardised proxy for renovation cost and running cost that sophisticated investors are increasingly using as a screen. Scraping EPC ratings at scale alongside listing prices lets analysts calculate true investment cost — listed price plus estimated energy upgrade — automatically.
The Digital Services Act and related EU data regulations also create a clearer framework for what constitutes legitimate automated access to public listing data — public pricing information displayed to all users remains accessible for commercial analysis in most EU jurisdictions, when extracted ethically.
Common Challenges and How to Solve Them
Site-specific rate limits: Major portals cap the number of listings returned per search query — often 500 to 1,000 results. The workaround is geographic segmentation: break large regions into smaller search boundaries (by postcode sector, neighbourhood, or radius) and aggregate results. This approach also improves data granularity.
Product matching across sources: The same property may appear on three different portals with slightly different descriptions, different listed prices (agencies sometimes vary their commission arrangements), and different photos. Deduplication and cross-source matching — using address normalisation and proximity clustering — is essential for clean data. Our post on AI-powered product data matching covers the underlying matching logic, which applies directly to property deduplication.
Data freshness: A listing price from three days ago may already be reduced. For investment analysis where you're tracking price reduction frequency as a negotiation signal, refresh cadence matters. High-velocity markets (London, Stockholm, Amsterdam) need at least daily refreshes on active listings. Slower markets can tolerate weekly cycles on stable stock.
Legal and ethical boundaries: Public listing data — prices, property attributes, agent information that any portal visitor can see — is generally fair game for commercial analysis in the EU and UK. Private communications, data behind authentication, or personal data of listed parties falls outside this boundary. Working with a managed scraping platform that maintains up-to-date compliance knowledge reduces this risk compared to ad-hoc in-house development.
Building vs. Buying Real Estate Scraping Infrastructure
For PropTech teams evaluating whether to build or buy, the calculation in 2026 has shifted significantly toward managed solutions.
Three years ago, building a real estate scraper in-house was a reasonable bet for a well-resourced engineering team targeting two or three portals. Today, the same effort requires maintaining proxy pools, handling fingerprinting from Cloudflare and DataDome, rebuilding extraction logic when portals update, and managing data normalisation across an increasing number of sources. That is a full-time infrastructure engineering project — before you've written a single line of business logic.
As Backlinko's research on operational efficiency consistently shows, teams that eliminate infrastructure maintenance from their core workflows allocate significantly more time to their actual competitive advantage. For a PropTech platform, that advantage is the product — not the scraping pipeline that feeds it.
Real estate data extraction as a managed service delivers structured property data on a defined refresh cadence, handles anti-bot defences, and keeps pipelines running through portal updates — without requiring engineering time for maintenance. For investment teams without dedicated engineering resources, it removes the infrastructure barrier entirely.
The right question is not "can we build this?" but "does building this create competitive advantage for us?" If your edge is investment strategy, market analysis, or product experience — not scraping infrastructure — the build path is a distraction.
Conclusion
Real estate data scraping has moved from a technical advantage to a baseline requirement for competitive property intelligence in 2026. The firms operating without automated data pipelines are not just slower — they are working with a fundamentally incomplete picture of the markets they operate in.
The data is publicly available on every listing portal. The question is whether you're capturing it systematically, at the refresh cadence your decisions require, from the sources that cover your target markets.
For investment teams and PropTech platforms ready to build that pipeline, book a call — structured property data from any public portal, delivered as a managed feed, without the infrastructure overhead.
Paste any URL — ScrapeWise handles the anti-bot
Managed infrastructure that adapts when sites change. No proxies, no code, no per-request fees.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →