Why Your Purchased Lead List Is Costing You Deals
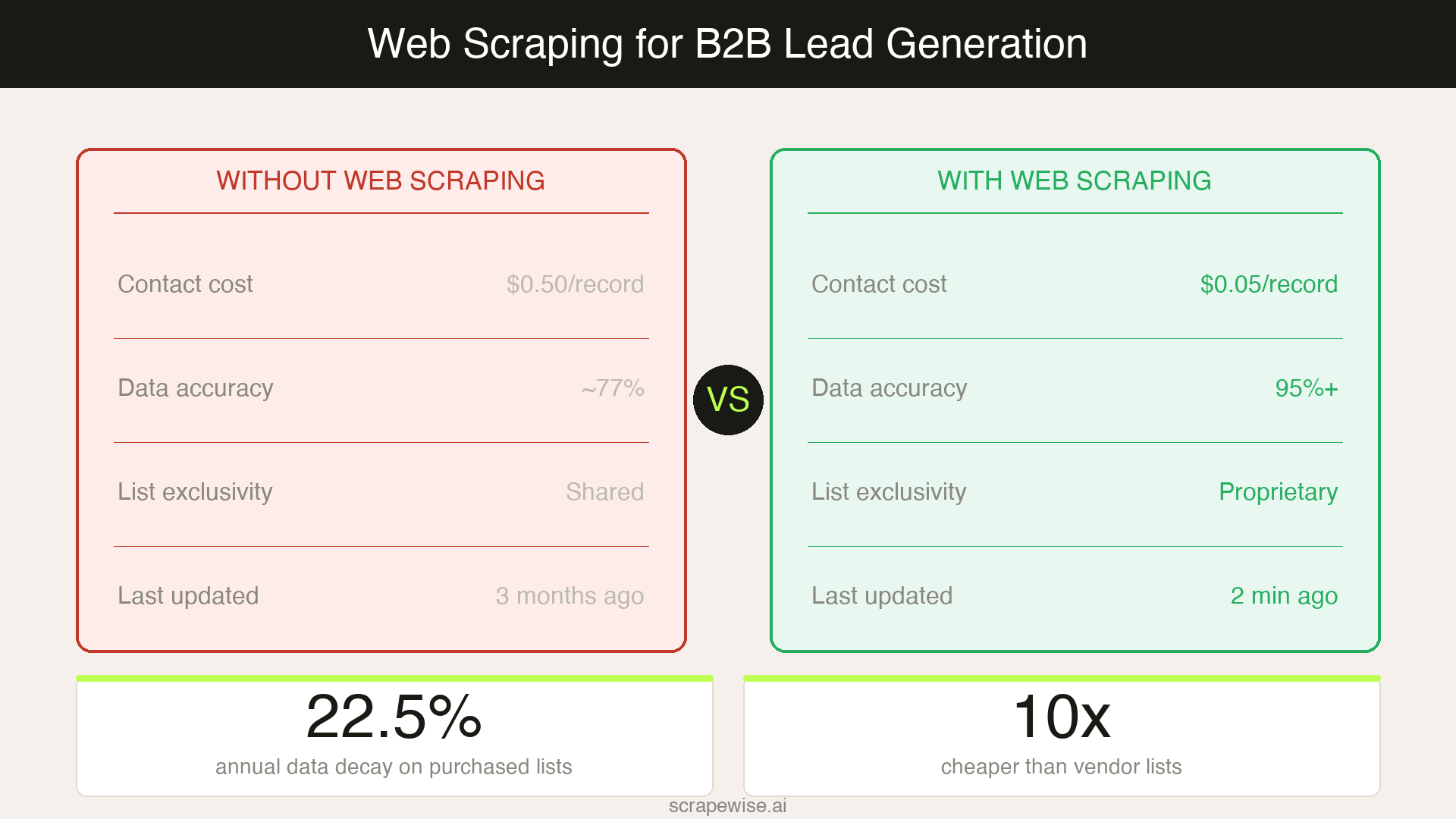
If your SDR team is still buying contact lists, you're paying $0.10–$1.00 per contact for data that was likely sold to a dozen competitors last month. B2B contact data decays at 22.5% annually, which means roughly one in four records in any list you buy today will be wrong within twelve months.
The result? Cold outreach that misses — 97% of cold outreach fails when targeting isn't precise. But the solution isn't better list vendors. It's owning your data pipeline. Web scraping for lead generation gives B2B sales teams a way to build real-time, signal-rich prospect lists from public web sources — without relying on stale databases or expensive subscriptions.
This guide is for SDRs, sales ops managers, and B2B marketers who want to understand how web scraping fits into a modern outbound pipeline — and how to do it without writing a single line of code.
What Is Web Scraping for Lead Generation?
Web scraping for lead generation means using automated tools to extract publicly available business information from websites — company profiles, contact details, job listings, funding announcements, technology footprints — and turning that data into qualified prospect lists.
The key word is signal. Unlike a static list from a data vendor, scraped data can be built around buying signals: a company that just raised a Series B, a business that's hiring five SDRs, a competitor's customer that posted a negative review on G2. These signals indicate intent and timing — the two factors that most determine whether outreach lands.
According to Forrester's B2B Sales Benchmark Report, companies with mature lead generation strategies achieve 133% greater revenue than those without. The maturity gap increasingly comes down to data quality and timeliness — and scraping addresses both.
Why Purchased Lists Are No Longer Competitive
The market for B2B lead data has a structural problem: vendors sell the same contacts to multiple buyers. By the time your SDR sequences a prospect, they've likely been hit by 5–10 other outbound teams already.
The economics make scraping look attractive. Purchased list costs run $0.10–$1.00 per verified contact. Scraping equivalent data through a managed provider typically costs $0.01–$0.10 per record — an order of magnitude cheaper, and fully owned by your team.
Add the decay problem. HubSpot's marketing data research puts annual B2B data decay at 22.5%, driven by job changes, company restructuring, and role evolution. A list scraped and verified this week reflects the web as it is today — not as it was when a database was last refreshed.
For European B2B teams in particular, the quality gap is sharper. DACH and Nordic markets tend to be under-indexed in American data vendors like ZoomInfo or Apollo. Scraping local business directories, Xing for German-speaking markets, and Scandinavian company registries often surfaces better-qualified contacts than any off-the-shelf tool provides.
The Four Signal Types That Make Web Scraping Powerful
The real advantage of web scraping for lead generation isn't volume — it's context. Here are the four signal categories that turn raw contact data into qualified pipeline:
Hiring Signals
Companies posting SDR, AE, or marketing roles are expanding their sales motion. A business hiring ten engineers suggests product-market fit and budget. Scraping job boards — LinkedIn, Indeed, and regional boards like Stepstone in DACH — and filtering for specific role types gives you a real-time view of company growth stages.
Funding and Growth Signals
Crunchbase, AngelList, and local company registries publish funding data. A company that closed a Series A three months ago has fresh budget and pressure to grow. Scraping this data systematically means you can build lists of "recently funded, headcount 10–100, SaaS sector" in minutes rather than hours of manual research.
Technology Stack Signals
Tools like BuiltWith and Wappalyzer expose the technologies running on a company's website. If you sell a product that integrates with Salesforce, a list of companies running Salesforce is your warmest possible audience. Scraping tech stack data turns ICP matching from guesswork into precision targeting.
Review and Intent Signals
G2, Capterra, and Trustpilot reviews reveal dissatisfaction with incumbents. A company that just left a three-star review for your competitor is a warm prospect — they're actively evaluating alternatives. Monitoring review platforms for your competitive set surfaces intent at the exact moment it occurs.
How to Build a B2B Lead Pipeline Using Web Scraping
You don't need to build your own scraper. Managed scraping services handle the infrastructure — proxy rotation, anti-bot evasion, data normalisation — so your team gets clean structured data without the engineering overhead. Here's the workflow:
Step 1: Define your ICP signals. Before scraping anything, map out what a qualified lead looks like in signal terms. Industry, headcount range, geography, tech stack, hiring patterns, funding stage — these become your scraping criteria.
Step 2: Identify your source stack. Match each ICP signal to a data source. LinkedIn for contact titles and company size. Crunchbase or national business registries for funding and firmographics. G2 or Capterra for competitive intent. Job boards for hiring signals. Local directories for regional European markets.
Step 3: Build or commission scrapers per source. Each source requires a separate scraper, maintained to handle layout changes. This is where managed web scraping removes the burden — instead of maintaining a fleet of scrapers yourself, you describe the data you need and receive a structured feed.
Step 4: Enrich and validate. Raw scraped data needs deduplication, email verification, and normalisation before it hits your CRM. Email verification is non-negotiable — invalid addresses damage sender reputation and deliverability.
Step 5: Push to your CRM and sequence. Structured, verified lead data integrates directly into Salesforce, HubSpot, or any CRM via CSV or API. From there, it feeds outbound sequences with the context signals intact — your SDRs know why they're reaching out, not just who they're reaching.
For teams already using automated scraping infrastructure, extending that infrastructure to B2B lead signals is a relatively small lift.
GDPR and Legal Compliance for European Teams
This is where most guides go vague — and where European B2B teams need clear answers.
Scraping publicly available business information is generally permissible under GDPR when:
- The data is used in a B2B context (not consumer or personal data)
- You have a legitimate interest in the outreach (commercial prospecting qualifies)
- You include a clear opt-out mechanism in all communications
- You do not store or process sensitive personal data
The key distinction is public vs. private data. Business email addresses listed on company websites, professional LinkedIn profiles, and public company registries are generally fair game for B2B prospecting. Personal email addresses and private consumer data are not.
For DACH markets specifically, be aware of the German UWG (Unfair Competition Act), which has stricter rules around cold email than GDPR alone. The standard practice in Germany is cold calling followed by email, rather than unsolicited email-first outreach. Adapting your sequence strategy by market protects compliance and improves conversion rates.
The safest operational rule: scrape business data, not personal data, from public sources, and always make opt-out easy. According to Ahrefs' guide to ethical data collection, the most defensible scraping operations are those built around publicly listed, business-context data with clear downstream compliance policies.
Integrating Scraped Lead Data Into Your CRM Stack
The bottleneck in most scraping-for-leads workflows isn't data collection — it's integration. Here's how to close that gap cleanly.
CSV enrichment is the simplest approach. Scraped data delivered as CSV, imported directly into your CRM. Works well for teams running weekly or bi-weekly list refreshes.
API feed suits continuous prospecting. A live API connection between your scraping provider and CRM means new leads flow in automatically as they're scraped. Turning web sources into structured API feeds is a core capability of modern managed scraping platforms.
Webhook-triggered enrichment suits high-velocity pipelines. A new company enters your CRM → a webhook triggers an enrichment scrape → additional data (funding, tech stack, hiring) populates the record automatically.
Whichever integration model you choose, keep one principle in mind: context travels with the contact. When an SDR sees a lead enriched with "raised €6M Series A, hiring VP Sales, running HubSpot," they write better emails. Signal-driven outreach consistently outperforms volume-driven outreach — and Backlinko's cold email research confirms that personalised cold emails get 2x the response rate of generic sequences.
What Changes When You Own Your Lead Data
The 44% of companies currently using automation for lead generation will grow to an estimated 70% by end of 2026, according to industry benchmarks. The teams moving first are building proprietary data moats — prospect lists and signal feeds that competitors can't buy from the same vendor.
When you own your lead data pipeline:
- You scrape fresh on demand — no waiting for vendor database updates
- You define the ICP criteria — not the data vendor's taxonomy
- You control the signals — hiring, funding, reviews, tech stack, in any combination
- You're not competing on the same recycled list as five other outbound teams
This is what first-party data strategy looks like applied to sales: a proprietary pipeline your team builds and owns.
Services like Scrapewise.ai are purpose-built for this use case — managing scraper infrastructure and delivering clean, structured data so sales teams get the output without the engineering overhead. For teams new to the approach, no-code data automation tooling provides a useful entry point before scaling to custom pipelines.
Where to Start
If your team is new to web scraping for lead generation, start narrow:
- Pick one high-value ICP segment
- Identify two or three public data sources that surface that segment (e.g., G2 reviews + a job board)
- Commission scrapers for those sources only
- Validate the output against your existing best-converting leads
- Scale the sources once you've confirmed the signal quality
Starting narrow keeps the investment low and the feedback loop short. Most teams see pipeline quality improvements within the first 30 days of switching from purchased lists to scraped, signal-enriched data.
Paste any URL — ScrapeWise handles the anti-bot
Managed infrastructure that adapts when sites change. No proxies, no code, no per-request fees.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →