Scrape JavaScript E-Commerce Sites in 2026: Beat Anti-Bot & Get Clean Data
In 2025, puppeteer-extra-stealth — the most popular tool for bypassing anti-bot on JavaScript-heavy sites — stopped receiving updates. Shortly after, Cloudflare rolled out detection that catches it reliably. If your scraping stack hasn't changed since 2024, it's probably already broken.
Modern e-commerce storefronts — React, Next.js, Nuxt, Angular — render prices, inventory, and reviews entirely client-side. Standard HTTP scrapers see a blank page. And even headless browsers now face five simultaneous detection layers before a single product price loads. This guide covers what actually works in 2026: the Playwright vs Puppeteer decision, the anti-bot stack, and when a managed scraping API beats DIY entirely.
Why JavaScript Sites Break Traditional Scrapers
Send a requests call to most modern e-commerce sites and you'll get back an HTML shell — no prices, no inventory, no reviews. The actual data is injected by JavaScript after the page loads. Traditional scraping (HTTP + CSS selectors) was built for static HTML and fails completely here.
The solution is headless browser automation: launch a real browser, let it execute JavaScript, then extract data from the rendered DOM. That's the theory. The practice is considerably harder.
Three real problems arise immediately:
JavaScript rendering overhead — each page requires a full browser launch, navigation, and render cycle. At 10 pages this is fine. At 100,000 SKUs, you need a distributed browser fleet.
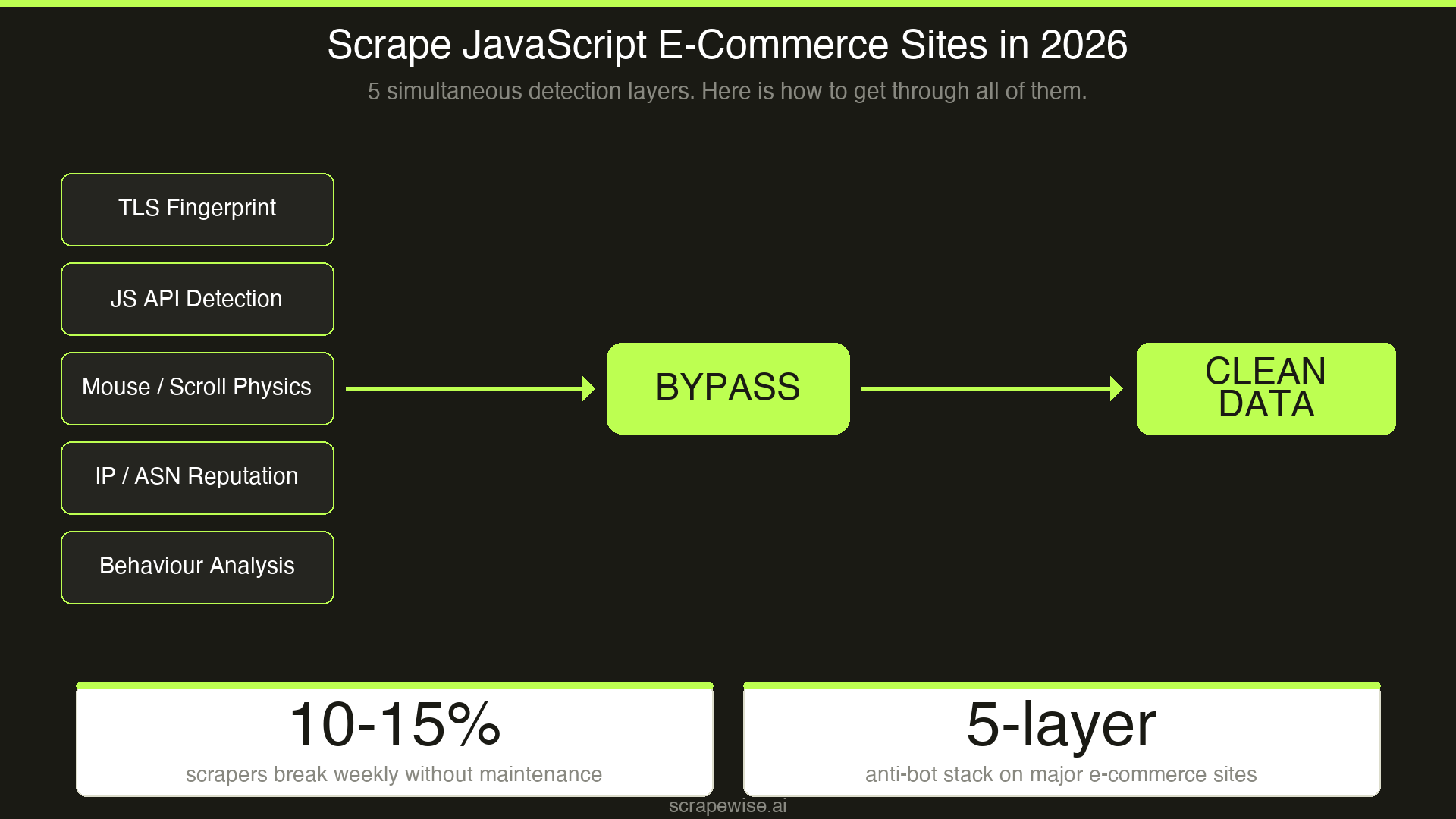
Anti-bot detection — Cloudflare, Akamai, DataDome, and PerimeterX now run five simultaneous detection checks before your request reaches any data. They're not checking your IP; they're analyzing your TLS handshake, your browser's JavaScript APIs, your mouse movement physics, and your scroll velocity.
Maintenance overhead — F5 Labs data shows approximately 10–15% of scrapers require weekly fixes due to DOM changes, fingerprinting updates, or endpoint throttling. At scale, scraper maintenance becomes a dedicated engineering role.
The 3-Layer Problem Every E-Commerce Scraper Faces
Before picking a tool, understand the three independent problems you're solving:
Layer 1: JavaScript rendering Your scraper needs to execute JavaScript and wait for the DOM to settle before extracting data. Headless browsers (Playwright, Puppeteer) solve this directly. Simpler alternatives like Splash or Selenium can work for basic cases.
Layer 2: Anti-bot bypass Even with a real browser, you'll be blocked. Modern systems check:
- TLS fingerprinting — your HTTP client has a unique signature even before the page loads.
curl-cffiimpersonates real browser TLS signatures to bypass Akamai's JA3/JA4 checks. - JavaScript challenges — Cloudflare injects JS that checks for headless browser markers: missing browser APIs, WebGL renderer strings, canvas fingerprints.
- Behavioral biometrics — mouse jitter, scroll velocity, and click precision are tracked before you interact with anything. A scraper that navigates directly to a button with mathematical precision gets soft-blocked. Data silently fails to load with no error thrown.
Layer 3: Infrastructure and scale Authenticated sessions (logged-in vs guest pricing), geo-blocked regional prices, JavaScript-loaded paginated SKUs, and rotating proxy management multiply complexity. According to ZenRows, most teams underestimate infrastructure cost by 3–5x when moving from prototype to production.
Playwright vs Puppeteer for E-Commerce Scraping: Which Wins in 2026?
| Factor | Playwright | Puppeteer |
|---|---|---|
| Browser support | Chrome, Firefox, WebKit | Chrome/Chromium only |
| Language support | Python, JS, TS, Java, C# | JavaScript/TypeScript only |
| Auto-wait for JS | Built-in | Manual implementation |
| Proxy management | Native rotation support | Third-party plugins required |
| Multi-step flows (login, cart) | Excellent | Good |
| Stealth / anti-bot | Growing ecosystem | Historically stronger |
puppeteer-extra-stealth |
N/A | Unmaintained since Feb 2025 |
| Performance (simple tasks) | Slightly slower | Faster |
Verdict for e-commerce scraping in 2026: Playwright.
The deprecation of puppeteer-extra-stealth is the decisive factor. According to BrowserStack's 2026 analysis, Puppeteer's stealth ecosystem has gone unmaintained precisely as Cloudflare updated detection to catch it. For e-commerce scraping — which involves multi-step flows, session handling, post-auth pricing, and scroll-triggered content loading — Playwright's built-in auto-wait, cross-browser support, and active stealth ecosystem (Camoufox, Nodriver) make it the better foundation.
Use Puppeteer when: you have an existing Node.js-only codebase, you're scraping simple Chrome-only targets, and you're layering your own stealth measures rather than relying on plugins.
Anti-Bot Bypass: What Actually Works Against Cloudflare and Akamai in 2026
The tools that worked in 2023–2024 have largely been patched. Here's the current state:
What no longer works:
- Rotating user-agents and custom headers — flagged years ago, still attempted
puppeteer-extra-stealth— unmaintained, Cloudflare actively catches it- Consumer VPNs / datacenter IPs — already in threat intelligence databases globally
What works in 2026:
1. Camoufox — A Firefox-based browser with deep fingerprint randomization. Effective against Cloudflare Turnstile and behavioral detection systems that look for Chrome-specific headless patterns.
2. SeleniumBase UC Mode — Uses undetected-chromedriver with patched browser binaries. Still one of the more reliable options for Cloudflare-protected targets as of Q1 2026.
3. Nodriver — A direct Chrome DevTools Protocol implementation that bypasses higher-level automation markers. Maintained actively and well-suited for complex e-commerce flows.
4. curl-cffi — For Akamai-protected sites, TLS fingerprint impersonation is the critical bypass layer. curl-cffi mimics real browser TLS handshakes, defeating JA3/JA4 fingerprinting before your request even reaches the application layer.
5. Residential or IPv6 proxies — IPv6 addresses are frequently cleaner in Cloudflare's threat scoring than IPv4 residential ranges. At scale, geo-targeted residential proxies are required for accurate regional pricing data.
The critical insight: Scrapfly's 2026 research on Cloudflare and Akamai confirms no single tool bypasses modern WAFs reliably. The working approach is always multi-layered: TLS impersonation + stealth browser + behavioral simulation + residential proxies, all simultaneously.
Step-by-Step: Scraping a JavaScript-Heavy E-Commerce Site with Playwright
Here's the practical architecture for a mid-scale e-commerce scraper (10,000–100,000 SKUs):
Step 1: Choose your browser context Use Playwright with a persistent browser context to maintain session cookies and avoid re-authenticating on every request. Set a realistic viewport, timezone, and locale to match your target's primary market.
Step 2: Layer in stealth Import Camoufox or patch your Playwright install to randomize browser fingerprints. Vary canvas fingerprints, WebGL renderer strings, and screen dimensions between sessions.
Step 3: Add behavioral simulation Don't navigate directly to product URLs. Simulate realistic entry paths — homepage → category → product. Add randomized scroll events and mouse movements before any data extraction. This is what defeats behavioral biometrics.
Step 4: Proxy rotation Route each session through residential proxies targeted to your scraping region. For European retailer monitoring, geo-targeted EU proxies are required — many retailers serve different prices by region, and datacenter IPs often see different (or blocked) content entirely.
Step 5: Handle async content
Use page.waitForSelector() or Playwright's built-in auto-wait to confirm price and inventory elements are rendered before extracting. Scroll-triggered content requires a scrollIntoView simulation before elements become visible in the DOM.
Step 6: Build for recovery Scrapers break. DOM structures change. Anti-bot systems update. Build retry logic, session rotation on block detection, and alerting for zero-result pages. For production pipelines, self-healing infrastructure that detects extraction failures and falls back gracefully is the difference between a prototype and a reliable data operation.
When a Managed API Beats DIY
The full DIY stack — Playwright + stealth + residential proxies + distributed infrastructure — solves the technical problem but carries significant ongoing cost. ScrapingBee's analysis of enterprise scraping costs consistently finds that teams underestimate maintenance and proxy costs by 2–4x at production scale.
The inflection point for most pricing and competitive intelligence teams is around 50,000–100,000 SKUs/month. Below that, managed platforms like ScrapeWise.ai handle the full stack — proxy management, anti-bot compliance, JavaScript rendering, data structuring — at lower total cost than maintaining your own infrastructure.
Above 500,000 SKUs/month, the economics can shift back toward a hybrid approach: managed APIs for protected targets, self-managed infrastructure for simpler ones.
The deciding factors:
- Do you have dedicated backend engineering time?
- Are you scraping 5 competitors or 500?
- Do you need structured, matched product data (not raw HTML) delivered?
- Are your target sites behind Akamai or Cloudflare? (If yes, managed APIs are nearly always faster to production.)
For a deeper look at the tradeoffs between DIY and API approaches, see web scraping vs APIs for retail data.
The Anti-Bot Arms Race: What's Coming Next
Cloudflare and Akamai are moving toward per-customer ML models that learn your site's normal traffic patterns and flag deviations. The anti-bot arms race is shifting from rules-based detection to behavioral AI — meaning no static bypass technique stays valid for long.
The emerging response is Vision-LLM-based scrapers that interact with pages as a human would, making DOM selectors irrelevant and behavioral detection substantially harder to trigger. Tools like GPT-4V-powered agents are already in early production use for highly protected targets.
For most e-commerce pricing teams, the practical implication is: don't build your competitive intelligence pipeline around any single tool or technique. Build for adaptability, and expect 20–30% of your extraction methods to need updating in any given quarter.
FAQ
What is the best tool to scrape JavaScript-heavy e-commerce sites in 2026? Playwright is the recommended foundation for new projects due to its multi-browser support, built-in auto-wait, and active stealth ecosystem. Pair it with Camoufox or Nodriver for anti-bot bypass. For production-scale pipelines targeting Cloudflare- or Akamai-protected sites, a managed scraping API is often faster to reliable data than a DIY stack.
Why is Puppeteer less recommended for e-commerce scraping in 2026?
The puppeteer-extra-stealth plugin — previously the standard bypass tool for Puppeteer — stopped being maintained in February 2025. Cloudflare has since updated its detection to catch it reliably. Playwright's ecosystem has moved ahead for complex, multi-step e-commerce scraping flows.
How do you bypass Cloudflare and Akamai when scraping e-commerce sites?
No single technique works reliably. The current working approach requires layers: TLS fingerprint impersonation (curl-cffi for Akamai), stealth browser with fingerprint randomization (Camoufox, Nodriver), behavioral simulation (randomized mouse movement and scroll before extraction), and residential proxies. All simultaneously.
How much does it cost to scrape JavaScript e-commerce sites at scale? DIY cost at 100,000 SKUs/month typically includes residential proxy fees ($50–200/month), infrastructure (browser fleet, queuing, storage), and 5–15 hours/month of engineering maintenance. Managed APIs simplify billing to a predictable per-request or volume tier. The true DIY cost is often 2–4x the licensing cost once maintenance is included.
What's the difference between scraping a regular website and a JavaScript-heavy e-commerce site?
Standard HTTP scrapers (Python requests, curl) retrieve HTML source code. On JavaScript-heavy sites, the HTML source is an empty shell — all product data loads after JavaScript runs. You need a headless browser to execute the JavaScript and wait for the DOM to render before any extraction is possible.
Conclusion
Scraping JavaScript-heavy e-commerce sites in 2026 is a three-layer engineering problem: JavaScript rendering, anti-bot bypass, and infrastructure at scale. Playwright has replaced Puppeteer as the recommended foundation, the old stealth plugin ecosystem is largely unmaintained, and modern anti-bot systems require a multi-layered approach combining TLS impersonation, behavioral simulation, and residential proxies.
For teams focused on competitive pricing intelligence rather than browser automation, managed platforms handle the full complexity and deliver structured product data directly. For teams building custom pipelines, the architecture outlined here reflects what's working in production today — with the caveat that the anti-bot landscape shifts fast, and any technique has a shelf life.
Related reading:
Paste any URL — ScrapeWise handles the anti-bot
Managed infrastructure that adapts when sites change. No proxies, no code, no per-request fees.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →