Scrapeless Alternative for E-Commerce Price Monitoring: 4 Tools Compared
Before you build your entire price monitoring stack around Scrapeless, there's a number you should understand: that 99.98% success rate claim in their marketing and across review sites. It sounds extraordinary. But when you dig into what it actually measures — and how it translates to real-world Amazon and eBay scraping — the picture gets more complicated.
This post breaks down what Scrapeless actually delivers for e-commerce price monitoring, where it falls short, and which alternatives make more sense depending on your team size, engineering capacity, and SKU volume.
What the 99.98% Success Rate Claim Actually Means
When Scrapeless — and several of its competitors — quote a 99.98% success rate, they're referring to proxy rotation success: the percentage of requests that reach the target server without being blocked at the IP level. That's a meaningful metric, but it's not the same as data extraction success.
A request can reach Amazon's servers and still return:
- A CAPTCHA page instead of product data
- A regional redirect that breaks your parser
- A throttled response with rate-limit HTML
- A product page with missing fields due to A/B test variants
Full scrape success — from HTTP request to structured, clean pricing data — is consistently lower. Independent benchmarks from AIMultiple's 2026 E-Commerce Scraper Rankings show actual data extraction success rates on Amazon and eBay vary from 85–98% across leading tools, depending on product category, time of day, and which anti-bot version is deployed.
Bright Data makes the same 99.98% claim for its Amazon scraping API — also applying to proxy-level reach, not end-to-end data delivery. This metric inflation is industry-wide, not unique to Scrapeless.
The real question isn't which tool claims the highest number. It's which tool delivers accurate, complete pricing data at the right cadence for your catalog — and who's responsible when it breaks.
The Decision That Changes Everything
Before comparing tools, there's one question that determines which category is right for you: do you have dedicated data engineering capacity?
Every scraping API — Scrapeless, Bright Data, Oxylabs, Apify — gives your team the capability to extract pricing data. The pipeline around that capability is your responsibility. Scheduling, deduplication, alerting, parser maintenance, and downstream data delivery are all on you.
When Amazon pushes a new Akamai Bot Manager update (which happens 4–6 times per year), you find out when your monitoring dashboard goes empty. When eBay redesigns their listing template, your parser breaks and competitor prices stop updating. Each update is a production incident for teams running their own scrapers — and a background fix for teams using a managed service.
Nordic and DACH e-commerce teams consistently cite this as the decisive factor. They didn't switch from self-serve APIs because of price. They switched because maintaining a scraping pipeline had become a half-time engineering job the business couldn't sustain.
If you have a dedicated scraping engineer: self-serve APIs give you maximum control and lowest API cost. If you don't: the "cheaper" API almost always costs more in engineering time than a managed alternative. Read more on how the anti-bot arms race affects DIY scraping teams.
4 Tools Compared: Quick Reference
| Tool | Best for | EU marketplace coverage | Engineering required | Est. monthly cost |
|---|---|---|---|---|
| Scrapeless | Eng. teams, US-focused | Limited | High | $300–600 |
| Bright Data | Large enterprise | Strong | High | $800–2,000+ |
| Oxylabs | Mid-market with eng. team | Good | Medium-High | $600–1,500 |
| Apify | Small teams, flexible | Moderate | Medium | $200–500 |
| ScrapeWise | Sales & pricing teams, any target | Strong | None | From €99/month |
Scrapeless
Scrapeless is a self-serve scraping API built around an AI-powered browser that handles JavaScript rendering, fingerprint rotation, and behavioural mimicry. It's genuinely well-built for teams with engineering capacity.
Best for: Engineering teams running US-focused monitoring across Amazon, eBay, and Walmart who want a lower-cost API than Bright Data or Oxylabs, with a pay-per-success billing model that eliminates wasted spend on failed requests.
Strengths: Pre-built structured data endpoints for major marketplaces. Pay only for successful responses. Entry-level pricing is competitive. AI browser adapts to anti-bot updates without manual scraper rewrites.
Limitations: You still own the full pipeline — scheduling, deduplication, alerting, and data delivery. European marketplace coverage (Amazon.de, Bol.com, Zalando) is less mature than US. When Amazon's anti-bot stack updates, success rates degrade before Scrapeless's AI catches up — which means gaps in your pricing data during those windows. No managed SLA if your pipeline breaks at 2am before a promotional event.
Bright Data
Bright Data is the market leader in commercial proxy infrastructure, with 150 million+ residential IPs across 195 countries. Their Web Scraper IDE and e-commerce dataset products let teams build custom scrapers or purchase pre-scraped datasets.
Best for: Large enterprises monitoring 50,000+ SKUs that need maximum IP diversity and have a dedicated data engineering team.
Strengths: The deepest proxy pool in the industry. Strong European marketplace coverage. Pre-scraped datasets are available for teams who want to skip the scraping layer entirely. The Bright Data vs Oxylabs comparison on Apify's blog breaks down how their infrastructure approaches differ.
Limitations: Pricing is complex — proxy bandwidth, scraping API calls, and dataset purchases are billed separately. Total cost of ownership for a 50,000-SKU setup can exceed $3,000/month when infrastructure maintenance is factored in. Significant engineering investment required to operationalise. Not cost-effective for teams monitoring fewer than 20,000 SKUs.
Oxylabs
Oxylabs competes directly with Bright Data on proxy quality, with adaptive AI-driven rotation that adjusts to website defences in real time. Their E-Commerce Scraping API delivers structured product data from Amazon, eBay, and major European marketplaces.
Best for: Mid-market to enterprise teams monitoring 10,000+ SKUs across multiple regional marketplaces with in-house scraping expertise.
Strengths: Strong European marketplace coverage including Bol.com and regional retailers. AI-adaptive proxy rotation performs well during anti-bot update windows. Structured product data API reduces parser maintenance compared to raw HTML scraping.
Limitations: Same DIY orchestration requirement as Scrapeless. Minimum contract tiers make it expensive for teams monitoring fewer than 5,000 SKUs. Their success rate claims apply to proxy-level delivery — actual data completeness depends on your parsing layer. See our full guide to scraping Amazon and eBay marketplace data for specifics on where structured APIs still require parser customisation.
Apify
Apify is a scraping platform built around reusable, community-built "actors" — containerised scrapers you deploy on their cloud infrastructure. Their marketplace includes pre-built Amazon and eBay scrapers maintained by third-party contributors.
Best for: Smaller e-commerce teams that want cloud-hosted scraping without managing servers, and can tolerate some variability in data freshness and quality.
Strengths: Lowest engineering overhead of the self-serve options — no server management. Large actor marketplace means you can often find a pre-built scraper for your target site. Competitive pricing at lower SKU volumes. Apify's own retailer price monitoring guide is worth reading for how they recommend structuring monitoring workflows.
Limitations: Community actors break silently when target sites update. For mission-critical repricing decisions, this is a real risk — you may not know your data has gone stale until a pricing decision has already been made. EU marketplace coverage is patchy depending on which actors are available and maintained. Not suitable for high-frequency monitoring (hourly or faster).
ScrapeWise
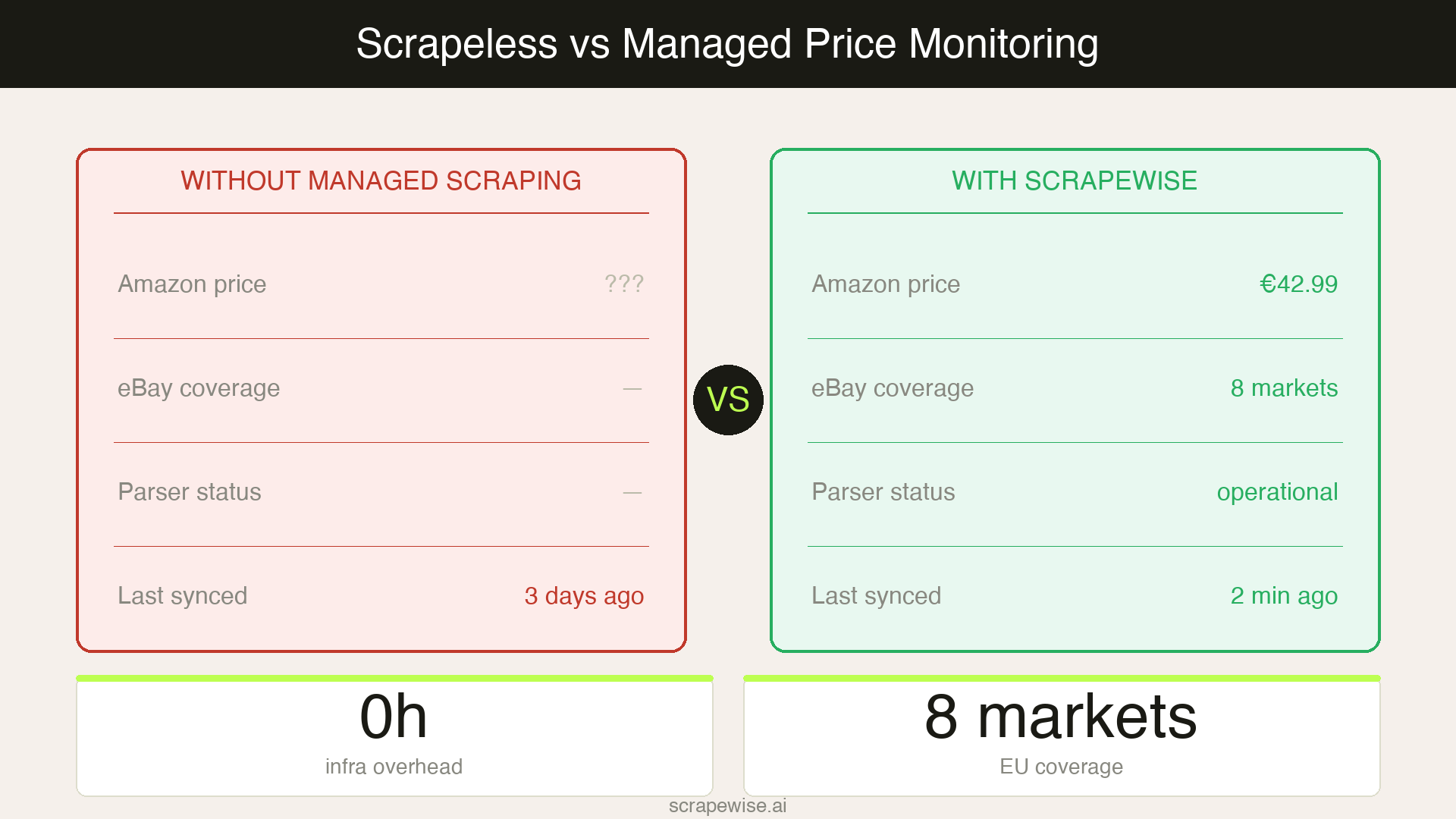
ScrapeWise takes a fundamentally different approach: instead of selling scraping infrastructure, it delivers the data. Pricing teams tell ScrapeWise which products and marketplaces to monitor, and ScrapeWise handles the scraping, anti-bot bypass, proxy rotation, and structured data delivery on a defined schedule.
Best for: Sales and pricing teams that need accurate competitor data delivered on a defined schedule — across any marketplace, retailer, or target site — without building or owning scraping infrastructure.
Strengths: No infrastructure to build or maintain. No parsers to update when Amazon or Zalando changes their page structure. Pre-built coverage for European marketplaces including Bol.com, Zalando, and Otto. When Akamai updates its bot detection, ScrapeWise adapts — your pricing pipeline keeps running. For teams focused on competitor price tracking, the difference is what you never have to think about. For a broader look at product data extraction beyond just pricing, the use-case page covers the full data flow.
Limitations: Not suitable for teams that need raw proxy access, custom scraper control, or want to build and own proprietary scraping infrastructure.
Pricing Breakdown: What These Tools Actually Cost
Direct comparisons are difficult because each tool meters usage differently. Here's a realistic cost framework for a mid-market retailer monitoring 10,000 SKUs daily across three marketplaces:
| Tool | Est. monthly API cost | Engineering overhead | Total cost reality |
|---|---|---|---|
| Scrapeless | $300–600 | Medium (build + maintain pipeline) | $600–1,200+ |
| Bright Data | $800–2,000+ | High (complex metering) | $1,500–4,000+ |
| Oxylabs | $600–1,500 | Medium-High | $1,000–2,500+ |
| Apify | $200–500 | Low-Medium (actor risk) | $300–800 |
| ScrapeWise | Custom at this volume | None | Custom |
At 10,000 SKUs across three marketplaces daily, ScrapeWise operates on a custom plan (900K+ rows/month exceeds self-serve tiers). Self-serve plans start from €99/month for smaller catalogs — suitable for teams monitoring a few hundred to a few thousand SKUs.
The "total cost reality" column is the number most buyers miss. A $400/month scraping API still requires engineering time to build, maintain, and debug. For teams where that time is better spent on pricing models, catalog management, or merchandising — the "cheap" API is rarely cheap.
Which Tool Should You Choose?
If you have a dedicated scraping engineer and your catalog is US-marketplace-focused: Scrapeless is a reasonable lower-cost alternative to Bright Data and Oxylabs with a better billing model.
If you need enterprise-grade infrastructure at scale with strong EU coverage: Bright Data or Oxylabs, with the understanding that you're signing up for significant ongoing engineering investment.
If you're a smaller team and can accept some data reliability risk: Apify reduces the infrastructure burden with the lowest upfront cost.
If your team's time is better spent on pricing decisions than data infrastructure: ScrapeWise eliminates the engineering overhead entirely and is built specifically for e-commerce teams who need pricing data delivered — not a scraping tool to build on top of.
The 99.98% success rate claim, whoever uses it, refers to a metric that happens before the data lands in your dashboard. What matters is accuracy, completeness, and reliability at the data layer — and that requires either excellent engineering or a managed service that owns the full stack.
Book a call — managed data delivery scoped to your coverage, no engineering required.
Paste a URL your current tool cannot reach
See why teams switch to ScrapeWise. 97% accuracy benchmark, no per-SKU pricing.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →