Bright Data Alternative for E-Commerce Price Monitoring: 5 Tools Compared (2026)
Most pricing teams comparing Bright Data alternatives spend hours on the $/GB table. They benchmark API costs, check proxy pool sizes, and count supported geographies. Then they sign a contract — and six months later, their engineering team is still fighting 403 errors, maintaining selector libraries, and rotating proxies instead of building anything useful.
The real cost of a web scraping infrastructure decision is not the API bill. It's the engineering hours. This guide compares five tools for e-commerce price monitoring on the metrics that actually determine total cost of ownership: anti-bot success rate, coverage across key marketplaces, how much engineering involvement is required, and what you actually pay versus what you expected.
The First Question: DIY Infrastructure or Managed Data?
Before comparing tools, identify which category of buyer you are. This single decision eliminates half the options on any comparison list.
You need DIY infrastructure if:
- You have an in-house engineering team comfortable maintaining scraper logic
- Your use case requires custom extraction schemas or unusual data structures
- You need to scrape at extremely high volume (10M+ requests/month) and want per-unit cost control
- You're already running Scrapy, Playwright, or Puppeteer and only need a proxy and anti-detection layer
You need managed data delivery if:
- Your pricing team — not an engineering team — is the primary user
- You need data on a predictable schedule without owning the pipeline
- You've already been through one or two DIY scraper failures and burned the goodwill
- You're monitoring Amazon, eBay, or Google Shopping, where anti-bot is a full-time problem, not a setup task
Bright Data, Oxylabs, and ScraperAPI sit firmly in the DIY infrastructure category. Zyte sits in between. ScrapeWise is managed delivery only.
If you're a mid-market retailer or a brand protection team — and your pricing analyst shouldn't have to file a ticket every time Amazon updates its page layout — the DIY category will cost you more than you expect over 12 months.
Quick-Reference Comparison Table
| Tool | Best for | Anti-bot handling | Engineering required | Pricing model |
|---|---|---|---|---|
| Bright Data | Enterprise at scale, diverse data types | Industry-leading proxy network, CAPTCHA solvers included | High — you own scraper logic and maintenance | $10.50/GB pay-as-you-go; committed plans from $500/mo |
| Oxylabs | High-volume DIY scraping, residential proxy coverage | Strong residential network, Real-Time Crawler product | High — scraper build and maintenance on you | $15/GB residential; enterprise custom |
| Zyte | Mid-market teams wanting partial automation | Automatic anti-bot, JavaScript rendering in API | Medium — Zyte handles connection, you handle schema | $25/1K URLs (API); custom for enterprise |
| ScraperAPI | Developer teams at smaller SKU volumes | Rotating proxies, JS rendering, basic CAPTCHA | Medium — you build the extraction layer | $49–$299/mo plans; custom above |
| ScrapeWise | Teams who want price data, not scraper infrastructure | Fully managed server-side; your team never touches it | Low — no selectors, no maintenance | Custom quote required |
Tool Breakdown
1. Bright Data
Best for: Enterprise teams with dedicated engineering resources who need a broad, general-purpose data infrastructure platform across many use cases.
Strengths:
- The largest commercial proxy network available — 72M+ IPs across 195 countries
- Scraping Browser handles JavaScript-heavy pages and CAPTCHA at scale
- Ready-made datasets and a data marketplace reduce build time for standardised use cases
- Strong compliance tooling with EU data residency options relevant to GDPR-conscious teams in Germany, the Netherlands, and France
- Detailed documentation and an active developer community
Limitations:
- Pricing is opaque at mid-market volumes — pay-as-you-go rates are high, and committed plans require negotiation
- You are renting infrastructure, not buying outcomes — if your scraper logic fails on a new target layout, that is your engineering team's problem to diagnose
- The $/GB benchmark figures reflect proxy layer performance, not end-to-end data delivery success rates — a distinction that matters for ops teams measuring actual data quality
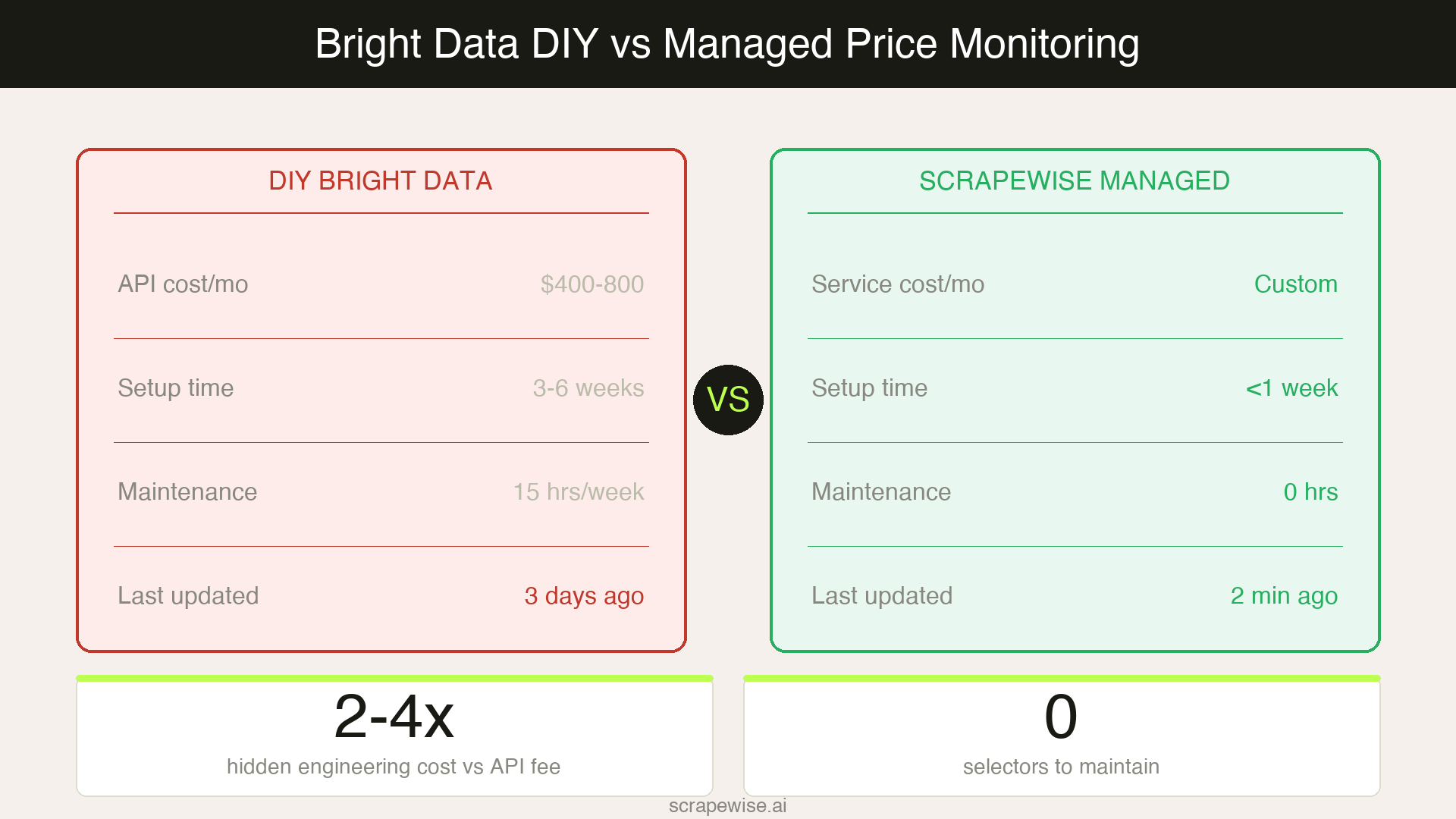
Total cost reality: A team running 500K product price checks per month at $10.50/GB will spend $400–800/month on API costs. Add one developer at 20% time maintaining the scraper at a typical mid-market salary, and real monthly cost runs $2,000–4,000. The API line item is the smaller number.
2. Oxylabs
Best for: High-volume scraping operations where residential proxy coverage and geographic breadth are the primary bottleneck.
Strengths:
- 100M+ residential IPs, considered one of the cleanest pools in the market for avoiding detection
- Real-Time Crawler product handles some anti-bot logic automatically, reducing raw proxy management work
- Strong coverage for Amazon, Walmart, and Google Shopping results
- Established compliance track record for European operations with GDPR-aware data handling
Limitations:
- Like Bright Data, you own the extraction layer entirely — Oxylabs provides the connection, not the data structure
- No price monitoring workflow tooling — it is a proxy and crawler layer, not a pricing intelligence product
- Residential proxy costs compound fast for continuous monitoring across large SKU sets
- Customer support response times decline meaningfully outside of enterprise-tier contracts
Total cost reality: Residential proxies at $15/GB run higher than Bright Data at comparable volume. For e-commerce price monitoring specifically, you are paying for infrastructure and still building everything above it.
3. Zyte
Best for: Mid-market teams that want more automation than raw proxies provide but are not ready to outsource the full pipeline — particularly teams already using Scrapy.
Strengths:
- Zyte API bundles smart proxy rotation, JavaScript rendering, and automatic anti-bot bypass in a single endpoint
- Reduces engineering overhead compared to managing raw proxies with a separate scraper framework
- AutoExtract feature infers product data fields from standard product pages without requiring custom selectors
- $25/1K requests is genuinely competitive pricing for structured extraction at moderate volume
- Good track record with European retailer pages that use Cloudflare or Akamai protection
Limitations:
- AutoExtract quality degrades on complex or non-standard layouts — B2B catalogues, distributor portals, and marketplace seller pages often require manual schema work
- Still requires engineering to define extraction schemas, handle edge cases, and build the monitoring pipeline around the API
- No native alerting or price change notification — you are building the workflow on top of the API response
- Scaling beyond 1M requests/month requires negotiating an enterprise contract with less transparent pricing
4. ScraperAPI
Best for: Developer teams at earlier-stage companies or with smaller SKU catalogs who want a simpler, more predictable entry point than Bright Data.
Strengths:
- Clean API that slots into existing Python or Node.js scraper code with minimal changes
- Automatic proxy rotation and JavaScript rendering included across all plan tiers
- Transparent monthly pricing ($49–$299) with clear limits — no mid-month $/GB surprises
- Fast onboarding for developers familiar with basic scraping patterns
- Reliable for scraping Amazon and eBay product pages at moderate request volumes
Limitations:
- Anti-bot success rate drops significantly on heavily protected targets using Cloudflare Enterprise, DataDome, or PerimeterX — the exact targets most e-commerce price monitoring use cases require
- You own the extraction layer entirely — ScraperAPI handles the connection, not the data structure or schema
- Rate limits on lower plans create monitoring frequency bottlenecks at scale
- No dedicated support for structured product data fields or price monitoring workflows
Total cost reality: The lowest TCO for developers building small-scale price monitoring. Breaks down reliably above 500K requests/month or on well-protected primary targets.
5. ScrapeWise
Best for: E-commerce teams, pricing managers, and brand protection teams who want clean, structured price data delivered on a schedule without owning or maintaining scraper infrastructure.
Strengths:
- Fully managed: no selectors to write, no proxies to configure, no JavaScript rendering decisions to make
- Anti-bot handling is a service-level responsibility — if a target updates its protection, ScrapeWise resolves it without a support ticket from you
- Structured output delivered directly to your data pipeline or analytics stack in your preferred format
- Covers heavily protected targets including Amazon, eBay, and Google Shopping — the same targets where DIY tools generate the most maintenance work
- Strong fit for competitor price tracking workflows and product data extraction at catalog scale
- Compliance-aware data handling for GDPR-regulated markets across Germany, the Netherlands, and the Nordics
Limitations:
- No self-serve access — getting started requires a discovery call and custom scoping; you cannot start same-day
- Custom pricing means there is no public rate card to compare against; evaluating the economics requires a conversation
- Not the right fit if you need general-purpose scraping infrastructure across 20+ diverse use cases beyond price monitoring and brand protection
Total cost reality: The per-request cost is higher than Bright Data's API rate. The 12-month total cost is often lower once you remove the engineering overhead — particularly for teams that have already run one failed DIY scraper project and understand the real maintenance burden.
The Total Cost of Ownership Calculation
The comparison that actually determines budget decisions looks like this:
| Cost component | Bright Data (DIY) | ScrapeWise (managed) |
|---|---|---|
| API / service fee | $400–800/mo | Custom |
| Engineering build (one-time) | $3,000–8,000 | $0 |
| Engineering maintenance | $1,500–3,000/mo | $0 |
| Failed run debugging | 3–6 hrs/week | $0 |
| Anti-bot failure mitigation | Your team's problem | Included in service |
| 12-month total estimate | $25,000–50,000 | Varies by scope |
This calculation is not designed to produce a specific outcome. It is the math most teams skip when they sign a scraping infrastructure contract. According to Gartner's analysis of total cost of ownership in technical procurement, hidden implementation costs routinely run 2–4x the headline license fee for infrastructure tools. Web scraping follows the same pattern.
If you have a dedicated data engineering team and need general-purpose scraping across 30+ use cases, Bright Data's infrastructure is worth the setup. If your primary use case is competitive price monitoring at catalog scale and your pricing team needs reliable data without owning the pipeline, managed delivery typically wins on total cost within six months.
For context on how the anti-bot landscape has changed the maintenance burden on DIY scrapers in 2026, see The Anti-Bot Arms Race.
How to Choose
Three questions to run before committing:
1. Who owns scraper maintenance in 12 months? If the answer is your pricing team, or "unclear," managed delivery removes that risk. If a named data engineer has bandwidth and the use cases are diverse, DIY infrastructure is viable.
2. What are your primary target sites? Amazon, eBay, Walmart, and Google Shopping require serious, continuously updated anti-bot capability. Validate each tool's actual success rate on these sites specifically — not on a benchmark the vendor designed. The real failure rate is what you discover after launch, not before.
3. What is your SKU volume and monitoring frequency? Under 50K SKUs with weekly monitoring: ScraperAPI or Zyte are cost-effective starting points. Above 100K SKUs with daily monitoring: engineering overhead on DIY tools compounds quickly and managed delivery starts to win on total cost.
For teams in the managed delivery category — or teams that have run the DIY path and want to model the real economics — get a data quote from ScrapeWise.
Paste a URL your current tool cannot reach
See why teams switch to ScrapeWise. 97% accuracy benchmark, no per-SKU pricing.
97% accuracy on Amazon benchmarks · no credit card · book a 15-min call →