The State of Retail Web Intelligence 2026: The Strategic Choice Between Web Scraping and APIs
The Invisible Data War
In 2026, the retail landscape is no longer defined by who has the most products, but by who has the most accurate data. As prices fluctuate by the hour and AI-driven personalized discounts become the norm, the "data gap" has become a boardroom-level crisis for global enterprises.
When retailers and data teams need external intelligence—competitor prices, real-time product availability, or localized campaign insights—one question dominates the architectural discussion: Should we use web scraping or an API?
While APIs were once seen as the “official” and clean solution and web scraping as the “flexible but fragile” alternative, the reality of 2026 is far more complex. Modern eCommerce sites have become so dynamic that the very definition of "data" has shifted. This report provides a comprehensive deep dive into the trade-offs of both approaches, designed to serve as the definitive guide for CTOs, Data Engineers, and Retail Analysts looking to build resilient intelligence systems.
The API Paradigm – Controlled Data Exchange
1.1 What Is a Modern API?
An API (Application Programming Interface) acts as a digital contract. It allows one system to expose structured data to another in a controlled, predictable way. In 2026, most major retail platforms offer some form of API access, typically returning clean JSON responses. These are designed for system-to-system communication, bypassing the visual elements of a website to deliver raw information.
1.2 The Core Strengths of APIs
Predictability is the primary benefit. APIs follow a strict schema. When you request a "price," you know exactly which field it will arrive in every single time. This consistency makes APIs incredibly easy to integrate into existing data stacks. Furthermore, standardized authentication layers like OAuth and modern API Keys ensure that data access is permissioned, tracked, and secure. From a technical standpoint, APIs also carry low computational overhead; because you are requesting raw data rather than rendering a full webpage, the bandwidth and CPU usage are minimal compared to browser-based tools.
1.3 The Strategic Limitations of APIs in 2026
Despite their technical cleanliness, APIs have inherent strategic "Blind Spots."
Providers only expose what they want you to see. A competitor will never offer a public API that exposes their most aggressive holiday discounting strategy or their real-time stock-out triggers. Additionally, API data often comes from a secondary "read-only" database that might lag 15–30 minutes behind the live frontend. In a world of dynamic pricing where Amazon or Walmart might update a SKU every two minutes, a 15-minute lag is a competitive liability.
The Web Scraping Revolution – Accessing the "Visual Truth"
2.1 Defining 2026 Web Scraping
Web scraping in 2026 is no longer about simple HTML parsing or regular expressions. It has evolved into "Frontend Intelligence Extraction." This process involves using AI-managed browsers to simulate a real user’s journey, extracting data exactly as it appears to a potential customer in a specific location.
2.2 Why Scraping Is Now "The Visual Layer"
On modern eCommerce sites, the "real price" often doesn't exist in the static source code. It is calculated in the browser via JavaScript, influenced by your zip code, your cookies, and even your scrolling behavior.
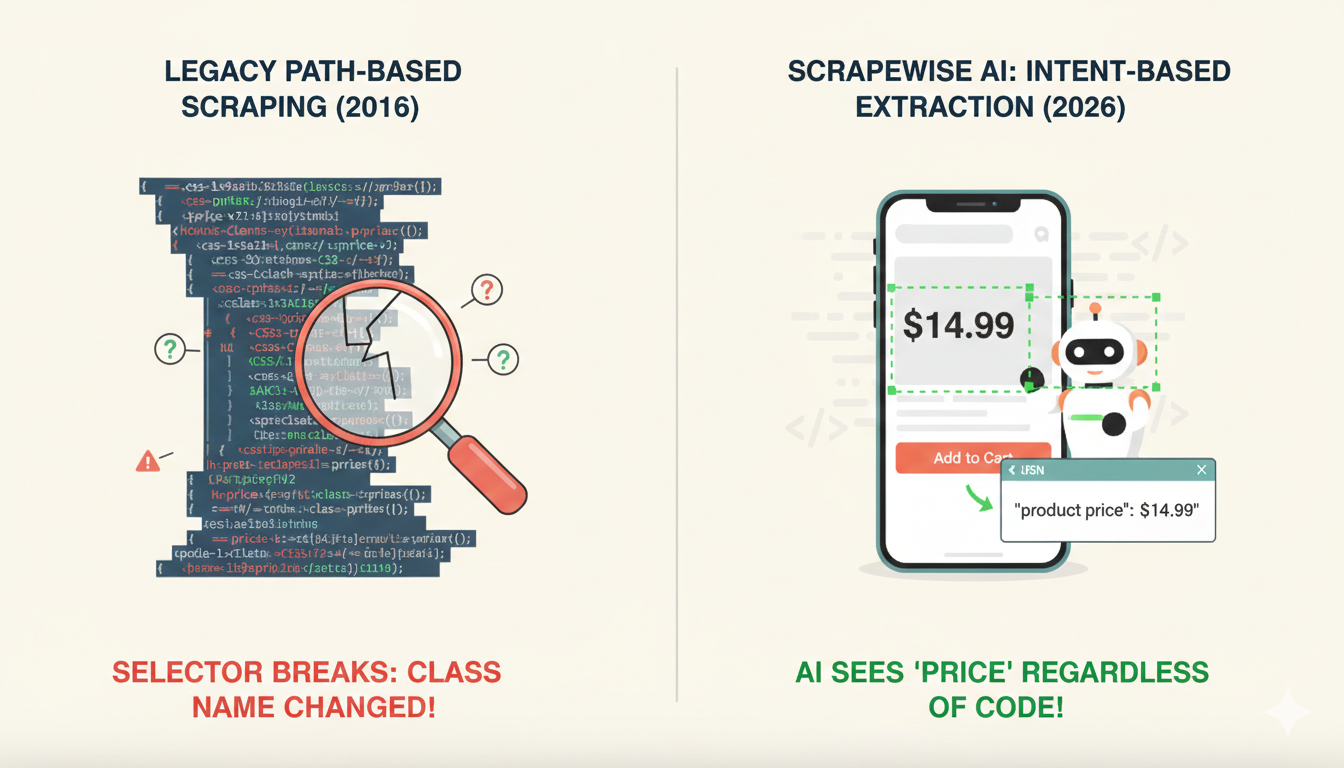
Modern scrapers execute the full frontend logic to see the final, rendered price. Furthermore, high-end scraping tools now use Computer Vision to "see" where the price is on a screen, bypassing the need for CSS selectors that can be easily obfuscated by developers.
2.3 The Flexibility and Market-Wide Advantage
Web scraping allows you to monitor any competitor, regardless of whether they "allow" it through an API. If the information is public on the web, it is accessible to a scraper. This makes it the only viable tool for comprehensive market analysis, as it treats the entire internet as a unified, queryable database.
Web Scraping vs API – A Structural Comparison
To build a high-performance retail system, you must compare these tools across several critical dimensions of operational efficiency.
3.1 Data Availability and Coverage
In the API world, coverage is at the mercy of the provider. If a marketplace decides to stop sharing "Stock Status" via their API to hide inventory struggles, your dashboard goes dark.
Scraping, however, offers 100% coverage of the public-facing site. It captures not just the price, but the "Visual Context": Is there a "Low Stock" badge? Is there a "Buy 1 Get 1" banner? Does the price change if you select a different color variant? For competitive intelligence, these visual cues are often more valuable than the raw price itself.
3.2 Data Freshness and the Race to Zero Lag
Many enterprise APIs rely on cached responses to save on server costs. This means the price you see through the API is a snapshot of the past.
Scraping is as fresh as the last page load. By hitting the live URL, you are seeing the exact price a customer would pay at that micro-second. This is the only way to power a "Real-Time Price Matching" engine that actually wins sales.
3.3 Reliability and the Maintenance Myth
Historically, scraping was seen as high-maintenance. However, the rise of AI-driven "Self-Healing" scrapers in 2026 has flipped the script.
Modern scrapers can automatically detect when a website moves a price from the sidebar to a floating header and adjust their extraction logic instantly. Neither approach is maintenance-free; APIs can be deprecated or changed without warning, requiring full development cycles to fix the integration.
The Technical Deep Dive – The Shadow Discount Problem
4.1 What Are Shadow Discounts?
Retailers in 2026 use complex frontend logic to show discounts only to certain users—for example, users coming from a specific social media referral or those browsing from a high-income zip code.
An API typically returns the standard MSRP or the "National" sale price. A scraper, using localized residential proxies and mimicking different user personas, can uncover these regional "Shadow Discounts," giving you the true picture of the competitive landscape.
4.2 Beating Advanced Anti-Bot Defenses
As of 2026, anti-bot systems have become incredibly sophisticated, using AI-driven fingerprinting and behavioral analysis. Legacy scraping scripts fail 90% of the time against these shields.
Modern scraping requires a "Managed Browser" approach, where the infrastructure handles CAPTCHA solving and browser realism automatically. This allows your team to focus on the data outcomes rather than the cat-and-mouse game of bypass technology.
Economic Impact and ROI for Retailers
The shift from legacy data collection to a modern intelligence pipeline isn't just a technical upgrade; it's an economic necessity.
5.1 The Cost of the "Data Gap"
When a competitor drops their price on a Friday evening and your API doesn't update—or your legacy scraper breaks—you don't find out until Monday morning.
In those 72 hours, you lose thousands of sales and your search ranking on marketplaces like Amazon or Google Shopping begins to slip. This "Data Gap" cost is often 10x higher than the cost of the scraping infrastructure itself.
5.2 Moving Beyond the "Maintenance Tax"
By utilizing an AI-native scraping platform like Scrapewise, companies eliminate the "Maintenance Tax"—the cost of paying developers to fix broken XPaths.
Instead, those engineers can be repurposed to build predictive pricing models and merchandising strategies that actually drive revenue.
Legal and Compliance Frameworks in 2026
The legal landscape for web data has clarified significantly, providing a safer environment for data-driven companies.
6.1 The "Public Truth" Doctrine
In 2026, global legal precedents have solidified the "Public Truth" doctrine: Data that is publicly visible to a human without a login is generally fair game for automated collection. Courts have recognized that restricting the collection of public price data would be anti-competitive.
6.2 The Responsible Scraping Protocol
To stay compliant, Scrapewise adheres to the 2026 "Responsible Scraping Protocol." This includes "Polite Rate Limiting" (never overwhelming a target's server) and automatic PII stripping, which ensures that no personally identifiable information is ever accidentally collected during a crawl. This protects your company from GDPR and CCPA violations while still providing the competitive edge you need.
The "Hybrid Architecture" – The Winning Strategy
The most resilient retail systems in 2026 don't choose one over the other; they use both in a "Complementary Data Loop."
7.1 How the Hybrid Model Works
In this model, you use APIs for "Internal Truth"—your own inventory, sales, and supply chain data—where security and structure are paramount.
You then use Web Scraping for "External Reality"—competitor moves and market trends where flexibility is required.
Finally, you use a Validation Loop where your scraper "audits" your own site to ensure your public-facing prices match your internal database. This prevents embarrassing pricing errors that can go viral on social media and damage your brand.
The Future of Agentic Commerce
As we look toward 2030, the very nature of the web is shifting toward "Agentic Commerce."
8.1 The Rise of the AI Shopper
Soon, humans won't browse websites; their AI agents will. These agents will use scraping-like technology to "read" the web and make purchasing decisions on behalf of the consumer.
If your brand’s data isn't structured and visible to these agents, you simply won't be considered. Mastering web extraction today is the only way to ensure your products are discoverable by the AI buyers of tomorrow.
8.2 Why Scrapewise Prioritizes "Accuracy Over Speed"
In the legacy era, scraping was a volume game. In 2026, it is an "accuracy game."
A single accurate data point that accounts for shipping, tax, and regional discounts is worth 1,000 cached API responses. At Scrapewise, we believe the future of retail belongs to those who see the web exactly as the customer does.
Key Takeaways for 2026 Data Leaders
- Context is King: APIs provide raw numbers, but scraping provides the visual context—the banners, the badges, and the layout—that actually drives a customer to click "Buy."
- Reliability has Evolved: AI-driven self-healing has eliminated the "fragility" excuse for web scraping. It is now as stable as any enterprise API.
- Shadow Pricing is Universal: To see localized and personalized discounts, you must use localized scraping proxies.
- The Hybrid Approach Wins: Use APIs for what you own; use scraping for what you need to conquer.
Data is Your Only Edge
The debate between web scraping and APIs is not a technical conflict—it is a strategic choice about how you view the market.
APIs offer a convenient, narrow window into a partner's data. Web scraping offers a panoramic, unvarnished view of the entire global market.
In a retail world where margins are razor-thin and competitors are relentless, you cannot afford to have blind spots.
By building a resilient, hybrid data pipeline that treats web scraping as a core intelligence asset, you ensure that your pricing strategy is built on the Visual Truth of the market, not just the filtered data an API allows you to see.